
14 Comments
In previous blogs, we talked about citation measures as one metric for scientific productivity. Raw citation counts are inherently problematic – different fields cite at different rates, and citation counts rise and fall in the months to years after a publication appears. Therefore, a number of bibliometric scholars have focused on developing methods that measure citation impact while also accounting for field of study and time of publication.
We are pleased to report that on September 6, PLoS Biology published a paper from our NIH colleagues in the Office of Portfolio Analysis on “The Relative Citation Ratio: A New Metric that Uses Citation Rates to Measure Influence at the Article Level.” Before we delve into the details and look at some real data, let me point out that this measure is available to you for free – you can go to our web site (https://icite.od.nih.gov), enter your PubMed Identification Numbers (PMIDs), and receive a detailed citation report on the articles that you’re interested in. And they don’t have to be NIH articles – you can receive citation measures (including the Relative Citation Ratio) on over 99.9% of articles posted in PubMed between 1995 and 2014. That’s well over 13 million articles!
Now, let’s take a look at how the Relative Citation Ratio (RCR) works.
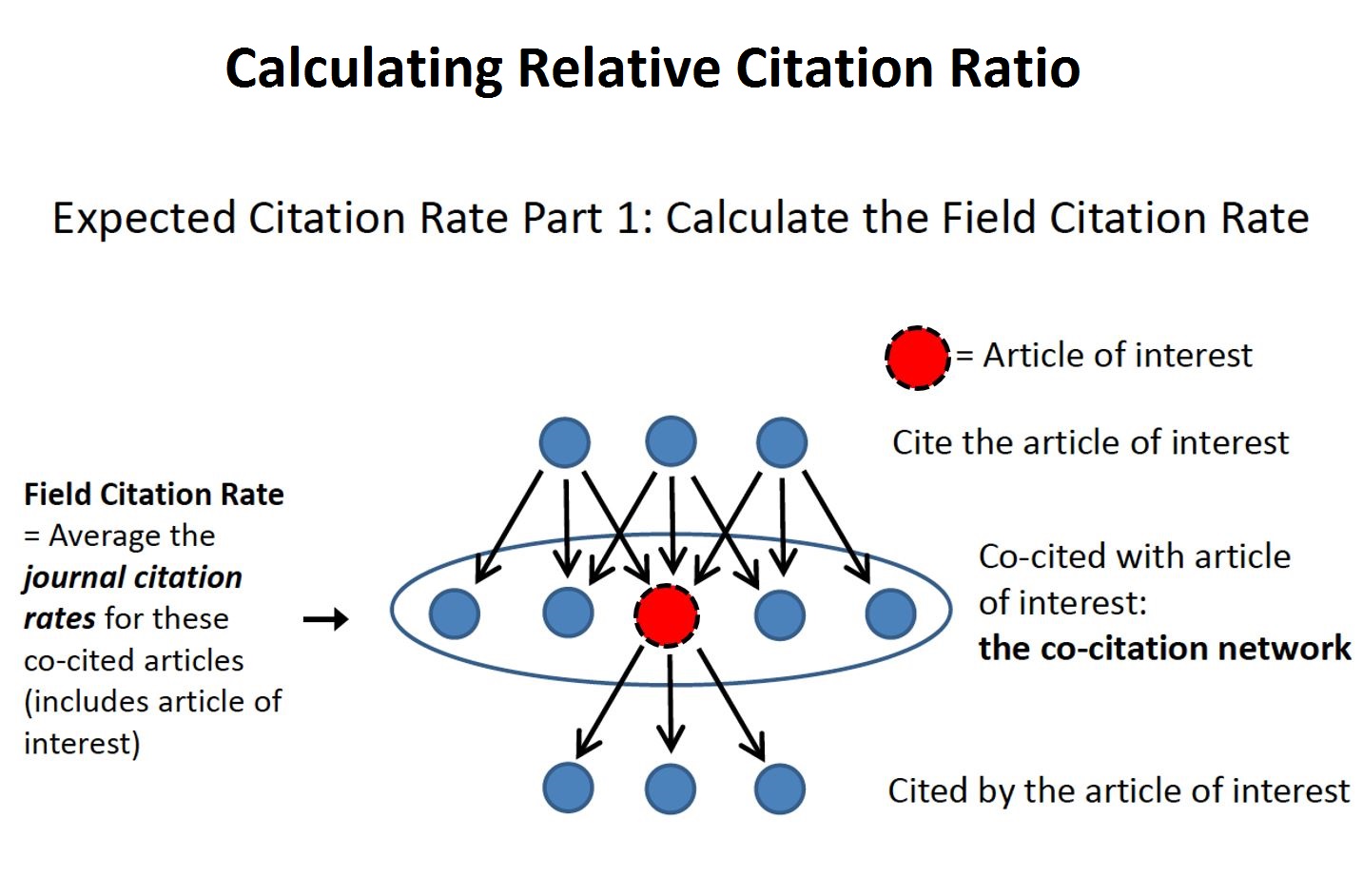
The goal of the Relative Citation Ratio is to quantify the impact and influence of a research article both within the context of its research field and benchmarked against publications resulting from NIH R01 awards. Figure 1 shows a red dot, our “article of interest.” It is cited by a number of articles (blue dots in the upper row), which we call “citing articles.” We can count the number of citations over time to our article of interest, yielding an “actual citation rate.” These citing articles not only cite our article of interest, but they also cite other articles, which we call the “co-citation network.” The corpus of co-citation network papers can be safely assumed to be reflective of the research field (or fields) of our article of interest. We can then calculate an estimated “field citation rate” by recording the citation rates of the journals that published the co-citation network papers.
In Figure 2, we show how to develop a benchmark measure for field-normalized citation rates by plotting the actual and field citation rates for a large cohort of NIH R01-supported articles.
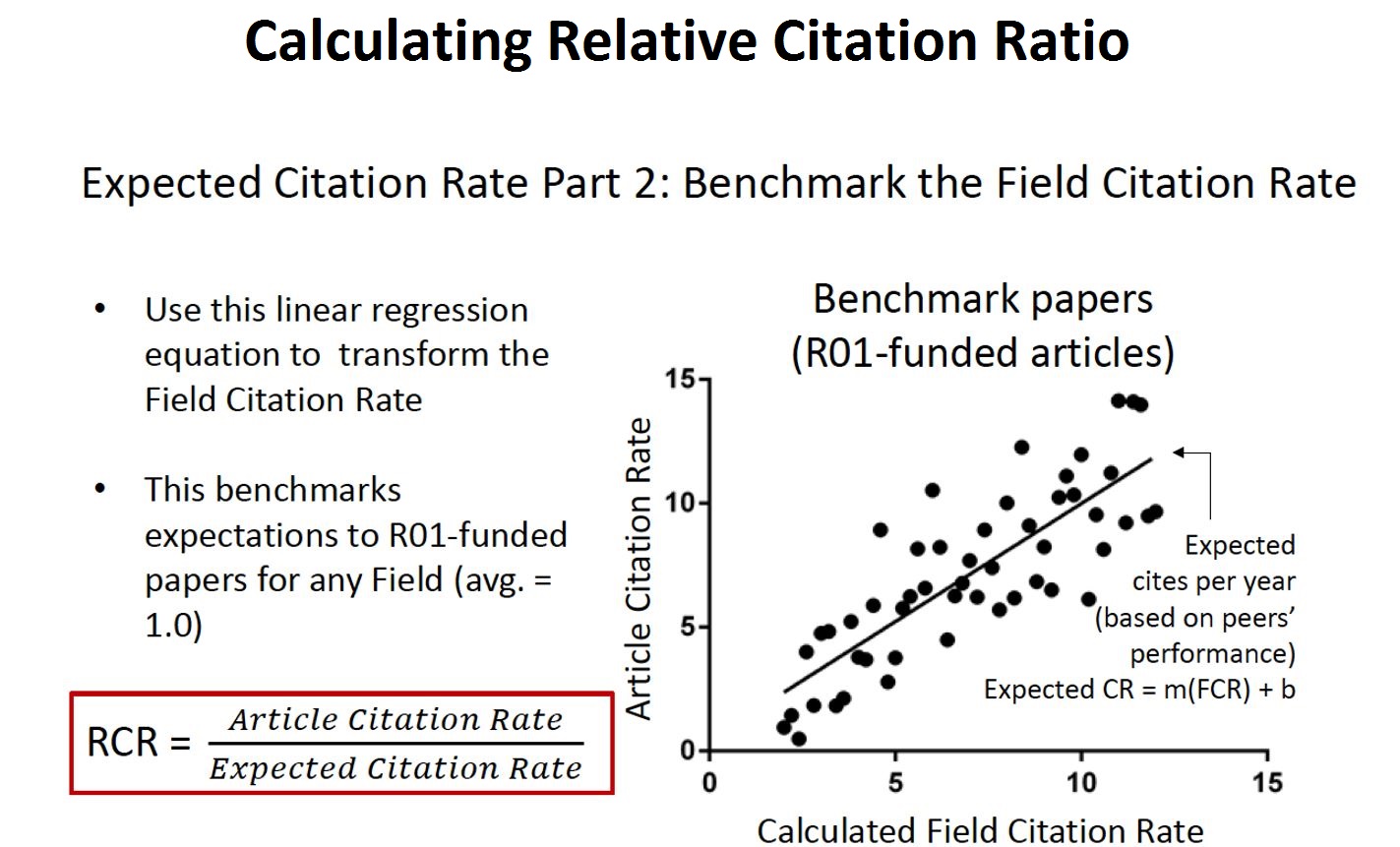
With this in hand, we can compare the actual citation rate to the expected citation rate (a rate that depends on field and time of publication and that is benchmarked to an “NIH norm”), yielding the relative citation ratio, or RCR.
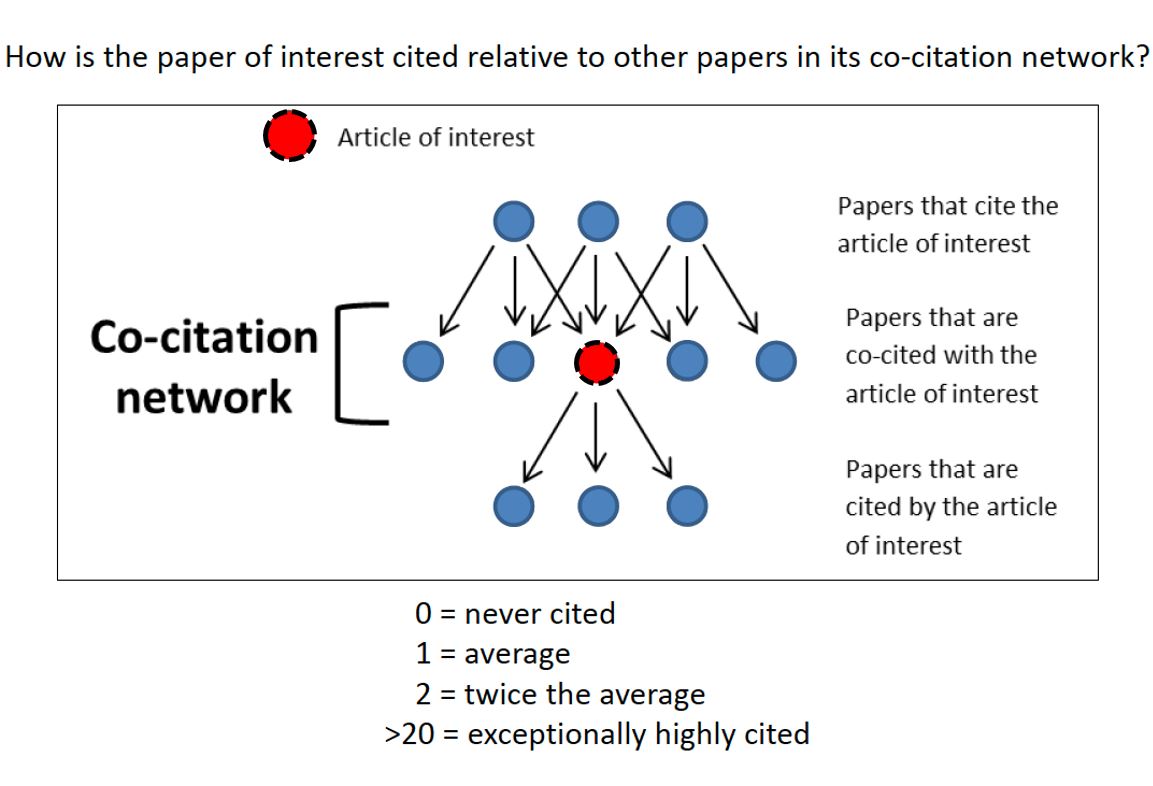
Figure 3 summarizes the process and what the results mean. If a paper is cited exactly as often as would be expected based on the NIH-norm, the RCR is 1. If a paper is never cited, the RCR is 0. If a paper is cited a great deal, the RCR will exceed 2, or 20, or even more.
So, now let’s look at some real data. We used NIH’s Scientific Publication Information Retrieval & Evaluation System (SPIRES) to identify over 1.4 million NIH-supported papers published between 1995 and 2014. SPIRES – as described in a 2011 Rock Talk blog, is an NIH system to map PubMed publications to NIH grants. (More about its capabilities is described in a manuscript published around the same time).
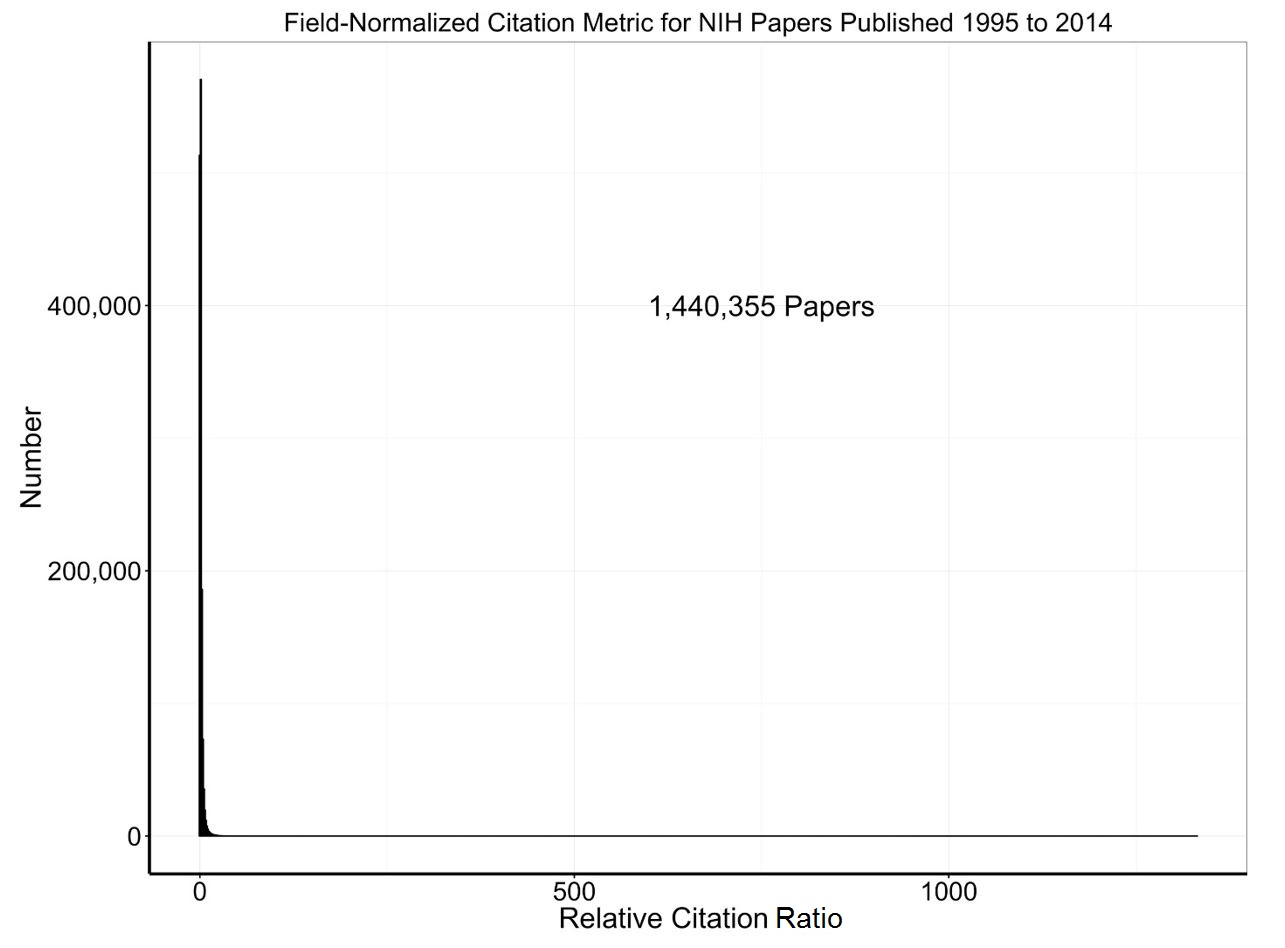
Figure 4 is a histogram showing the spread of RCR – note that there is a highly skewed – very very skewed! – distribution with most papers have low RCR values but a few having high, even extremely high values. This is consistent with patterns described in previous literature on scientific citations.
To make these data more informative, let’s look at Figure 5 in which we log-transform the X-axis. Now we see a (not quite) log-normal distribution with a median value of 1 (as would be expected for NIH papers). There are a few papers with RCR values of zero – now easy to see – while the large mass of papers have RCR values between 0.1 and 10.
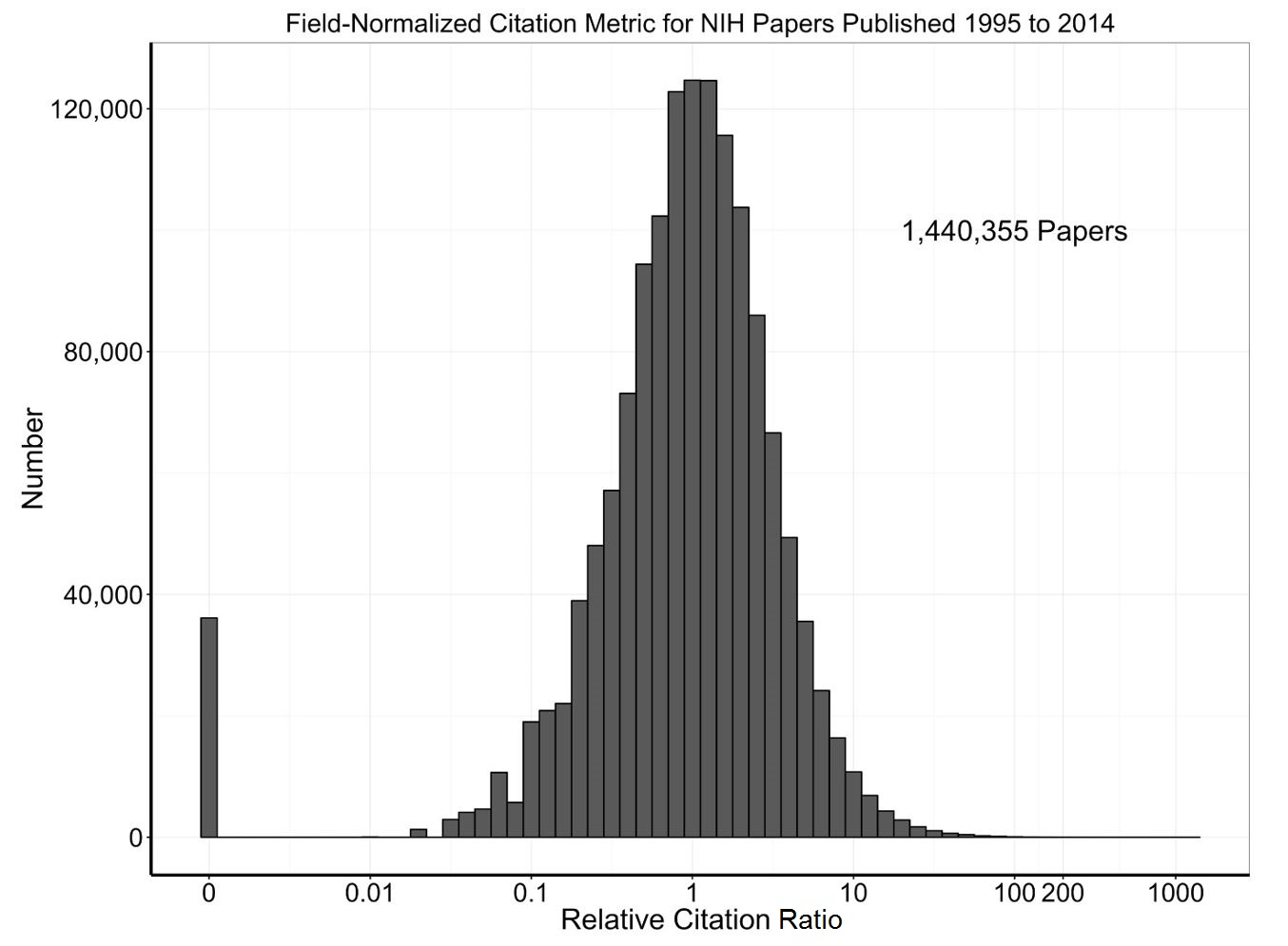
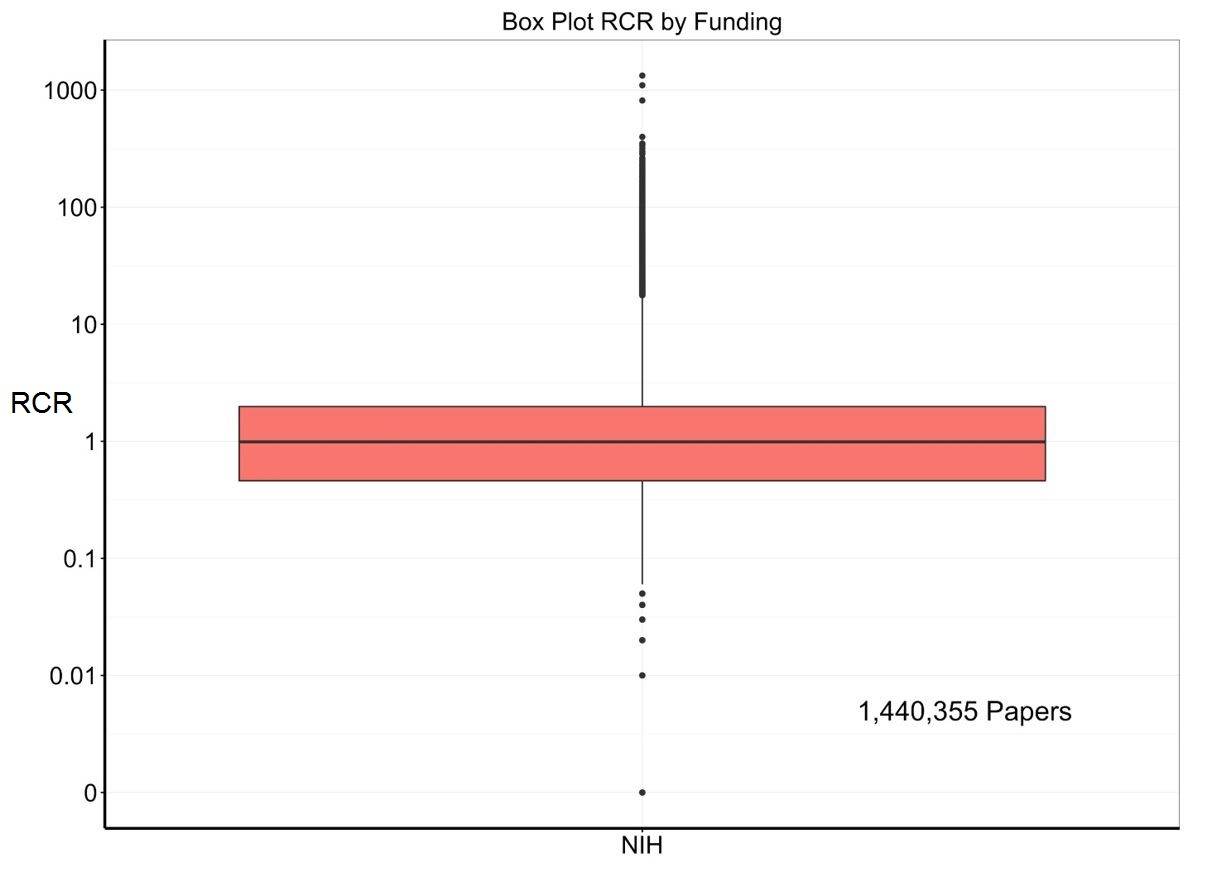
Figure 6 shows another way to present these data – a box plot. The median (middle black line) is 1, while the 25th and 75th percentiles (bottom and top of the box) are 0.46 and 1.98. It turns out that NIH papers comprise about 11% of all PubMed entries. Figure 7 adds a box plot for nearly 12 million papers that were not supported by NIH: the median is much lower at 0.36 while the 25th and 75th percentiles are 0.06 and 0.96.
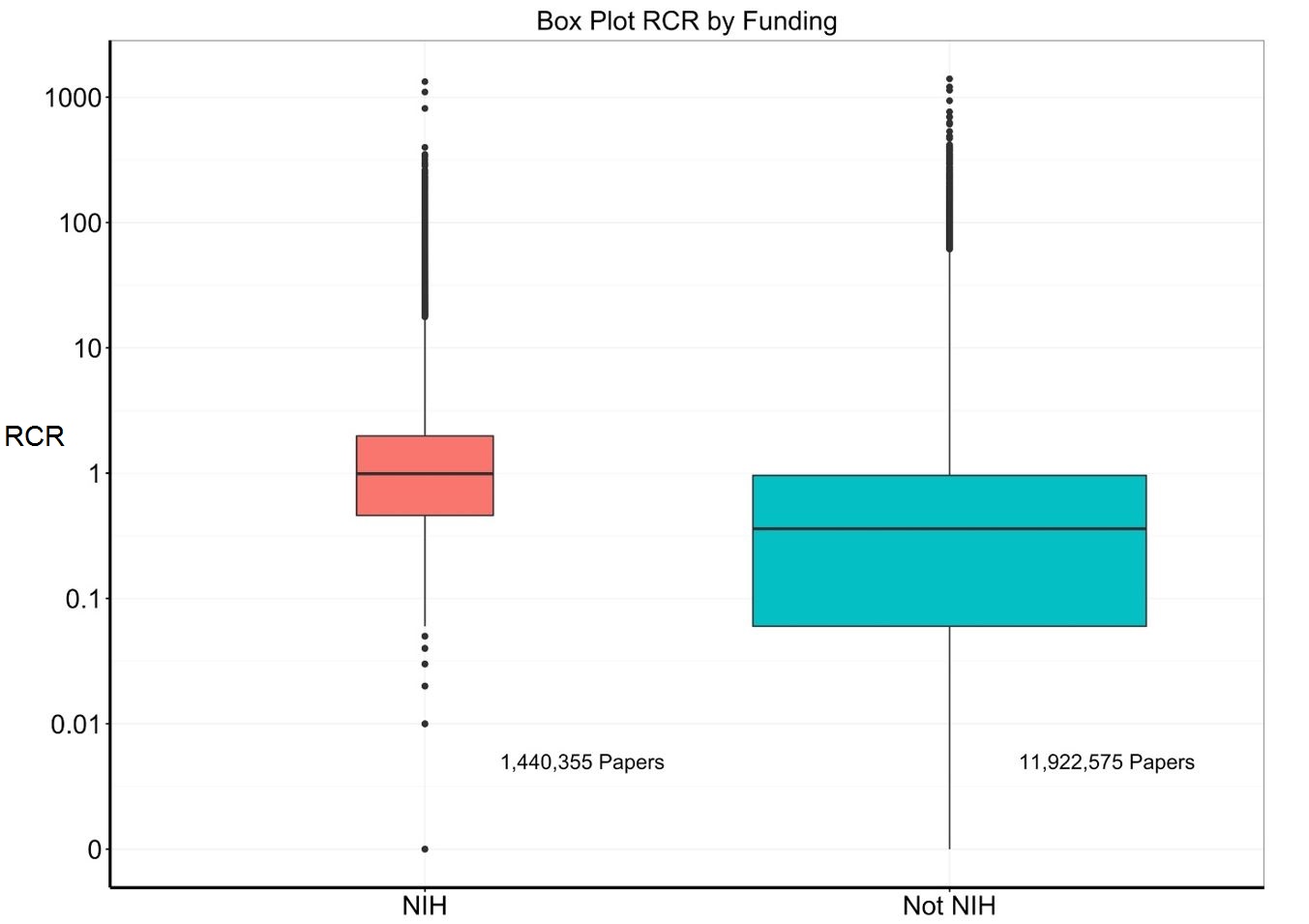
Just by looking at the two box plots side by side, we can see that on the whole, NIH papers have higher RCRs. However, there are NIH and non-NIH papers with extremely high values (greater or much greater than 20).
However, this is not the whole story. We can better show these data by superimposing density distribution plots over the box plots (aptly called “violin plots”). Figure 8 shows violin plots and we see that there is a much larger group of papers with RCR values of zero among the non-NIH papers.
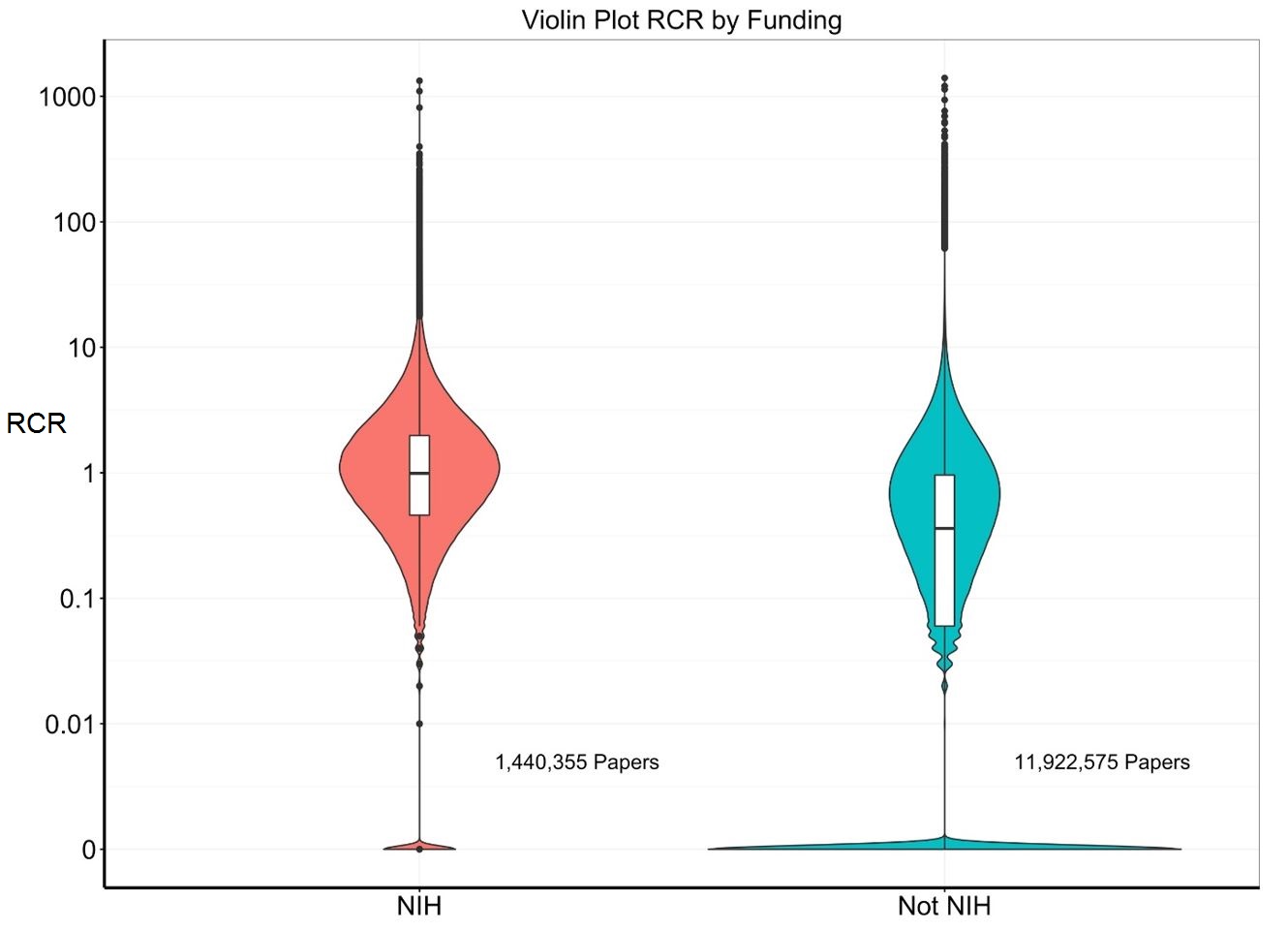
In fact, we found that 3% of NIH papers were never cited, while over 20% of the non-NIH papers were never cited.
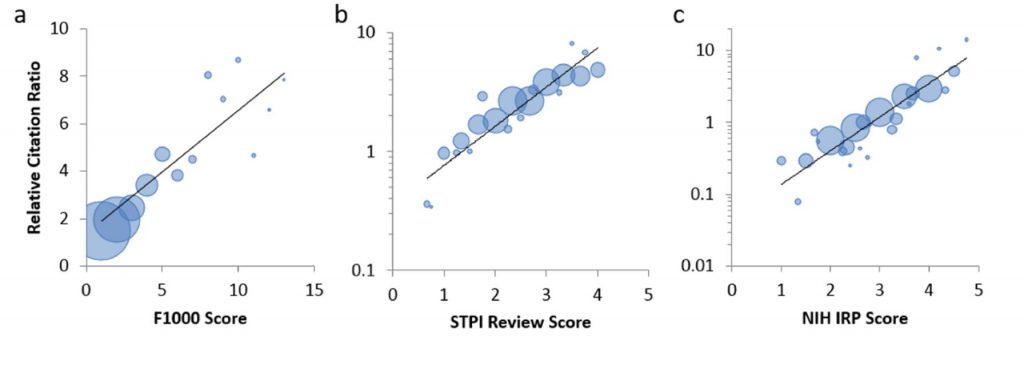
One obvious question is whether these values really mean anything in terms of scientific quality. Yes, we can count citations and make some fancy calculations, but do these have anything to do with high-quality science, the kind of science that we at NIH most want to support. The authors of the PLoS Biology paper present data (Figure 9) from 3 separate studies in which expert peer reviewers rated a group of papers; in all 3 cases, there was a strong association between scores by expert opinion and RCR.
What’s next? We would strongly encourage you to read the PLoS Biology paper and to go to the NIH Office of Portfolio Analysis’ iCite page so you can try it yourself.
In future blogs we will revisit some prior questions and look at others leveraging the RCR. For example, we can look at the association of grant budgets and grant durations with productivity as assessed by RCR. We can, as some of you suggested before, compare outcomes for different scientists, different organizations, and different types of grants. We can also consider other outcomes, like submission or publication of patents. We’ll also look at other tools that enable us to trace the development of discoveries over time and to follow a field from basic to translational to applied work. And please feel free to send us your questions about analyses we or others should do so that we can work together to make the field of grant-funding one that is more and more grounded in evidence.
Congratulations to the authors of the PLoS Biology paper. I would like to thank the Office of Portfolio Analysis for helping me learn about the Relative Citation Ratio. I would also like to thank my colleagues in OER (including the Statistical Analysis and Reporting Branch and the Office of Data Systems) for helping me with these analyses.
How is “field” decided in this calculation? It would really matter in regard to RCR and percentile, but I can not find any information on even what field a particular set of papers is being compared to…
See Figure 3- the co-citation network is a custom field for each paper.
Does that mean that two papers from the same lab funded by the same grant can have the same number of citations but a different RCR if they are referencing a different subset of the scientific literature then?
Thinking about this… If I understand the metric used, a paper is compared against the number of other citations that papers in the reference list received. If so, this seems like an easy way to game the metric by only referencing the lesser known articles (particularly reviews) in the manuscript. If you reference too many highly cited papers, wouldn’t this change the comparison pool and possibly tank the RCR of a paper?
While I really like the idea of comparing papers within their field, all of these measures do have the potential to be gamed just like the current impact factor already is…
It is not the average number of citations for the papers in your reference list. Rather, the papers in the reference lists of the papers that cite your paper are taken into account. And not their individual citation rate, but rather the average citation rate of the journals publishing them.
I shudder at the announcement of yet another metric that will be used/abused to evaluate the productivity and worth of individual researchers. How do you distinguish science that is poorly cited because the work is ahead of its time from science that is highly cited because it is the fad of the moment? Is there any correction for authorship where the author is one member of very large consortium, such as ENCODE, putting out many highly cited papers, vs someone running a small laboratory with few collaborations? I am concerned that, like other metrics (journal impact factor, etc.), this will be yet another way to push people into trying to publish papers that will be highly cited rather than focusing on innovative and difficult science. Whatever happened to DORA?
Thanks for your comment – we agree that metrics need to be used in a suite of tools to assess scientific productivity. The RCR is a multi-faceted metric which does address some of the concerns you mention, such as the temporal context of papers that may be ahead of their time, and benchmarking within the appropriate subfield. You might be interested in reading this review of the RCR paper from the director of the American Society for Cell Biology, the society that initiated the Declaration on Research Assessment (DORA).
Well, wouldn’t papers that are innovative be highly cited anyway? In the past, it took some time. But, now with the heated competition, fellow researchers will jump at the chance to push ahead with something that is new and useful. We need some metric – too much junk science and copycat research being published these days. I see a potentially novel study on one particular cancer published, and quite soon floodgates open on the same, using every conceivable type of cancer imaginable. Nowadays, there are far too many researchers who are incapable of an original thought! Impact factors may not be perfect, but, they are a much better metric than simply counting numbers – these days one can get a fake peer reviewed publication for a few hundred bucks and then get it into PubMed Central and eventually into PubMed. Unfortunately, those who want to game the system always find a way!
The RCR sounds similar to Elsevier’s Field-Weighted Citation Impact (FWCI). I wonder what advantage the RCR provides or whether they have been compared.
Another statistic to make sure new applicants have an even harder time getting their first grants.
Where do you weigh the 60% to 80% of federal funded work that is not reproducible?
In my opinion, this paper counting does not make better data
Interesting. I wonder about two potential issues:
1) Doesn’t this metric ‘punish’ inter-disciplinary articles? These articles will have a larger cohort. For example, consider a hypothetical psychology paper that *also* gets cited in computer science journal with lots of other articles. Unless this paper performs up to both the psych and computer science cohort, the RCR will make it look bad, won’t it? (and that would go against the intuition that this is an influential inter-disciplinary article).
2) The RCR is a ratio and thus very vulnerable to low counts in the denominator (unless the RCR is somehow smoothed? in that case, low count data will cluster around the smoothing target). But perhaps all cohorts—and thus expected citation counts—are large enough to make this a non-issue?
I think citation alone is problematic. Let’s give an example here. C-kit+ cells were claimed to be cardiac progenitor cells. Subsequently there were numerous papers about c-kit, and a large amount of them are highly cited. For example, Adult cardiac stem cells are multipotent and support myocardial regeneration, Cell. 2003 Sep 19;114(6):763-76. Citations: 3219!
NIH has invested hundred of millions of dollars based on the assumption that these claims were real. Unfortunately, recently several solid papers directly refuted the notion that c-kit+ cells are cardiac progenitor cells (e.g. C-kit+ cells minimally contribute cardiomyocytes to the heart. Nature. 2014;509:337-341). At least one of c-kit papers was retracted. It’s safe to say that most of previous papers about c-kit are actually wrong. Peer review but not citation can tell you the truth!
You need to get rid of review articles!
I missed this blog when first published but have just plowed through the PlosBiology paper and feel the RCR deserves to be considered as a valid indicator. I don’t think it will replace average article cites or h-index but it does normalize things a bit. Reminds me of the NCAA RPI that rates teams 50% on their opponents records and 25% on their opponents opponents records and only 25% on their own record. Of course this is abused by the power conferences but any numeric indicator will be abused. Now of course I feel obligated to go to icite and calculate RCRs for recent work (I am relatively new to NIH having spent most of my career in “low cite” chemical physics research).