
20 Comments
In a recent PNAS commentary, Daniel Shapiro and Kent Vrana of Pennsylvania State University, argue that “Celebrating R and D expenditures badly misses the point.” Instead of focusing on how much money is spent, the research enterprise should instead focus on its outcomes – its discoveries that advance knowledge and lead to improvements in health.
Of course, as we’ve noted before, measuring research impact is hard, and there is no gold standard. But for now, let’s take a look at one measure of productivity, namely the publication of highly-cited papers. Some in the research community suggest that a research paper citation is a nod to the impact and significance of the findings reported in that paper – in other words, more highly-cited papers are indicative of highly regarded and impactful research.
If considering highly-cited papers as a proxy for productivity, it’s not enough that we simply count citations, because publication and citation behaviors differ greatly among fields – some fields generate many more citations per paper. Furthermore, citation counts vary over time: it would not be fair to compare a paper published in 2013 with one published in 2008, as the latter paper has had 5 more years to generate citations.
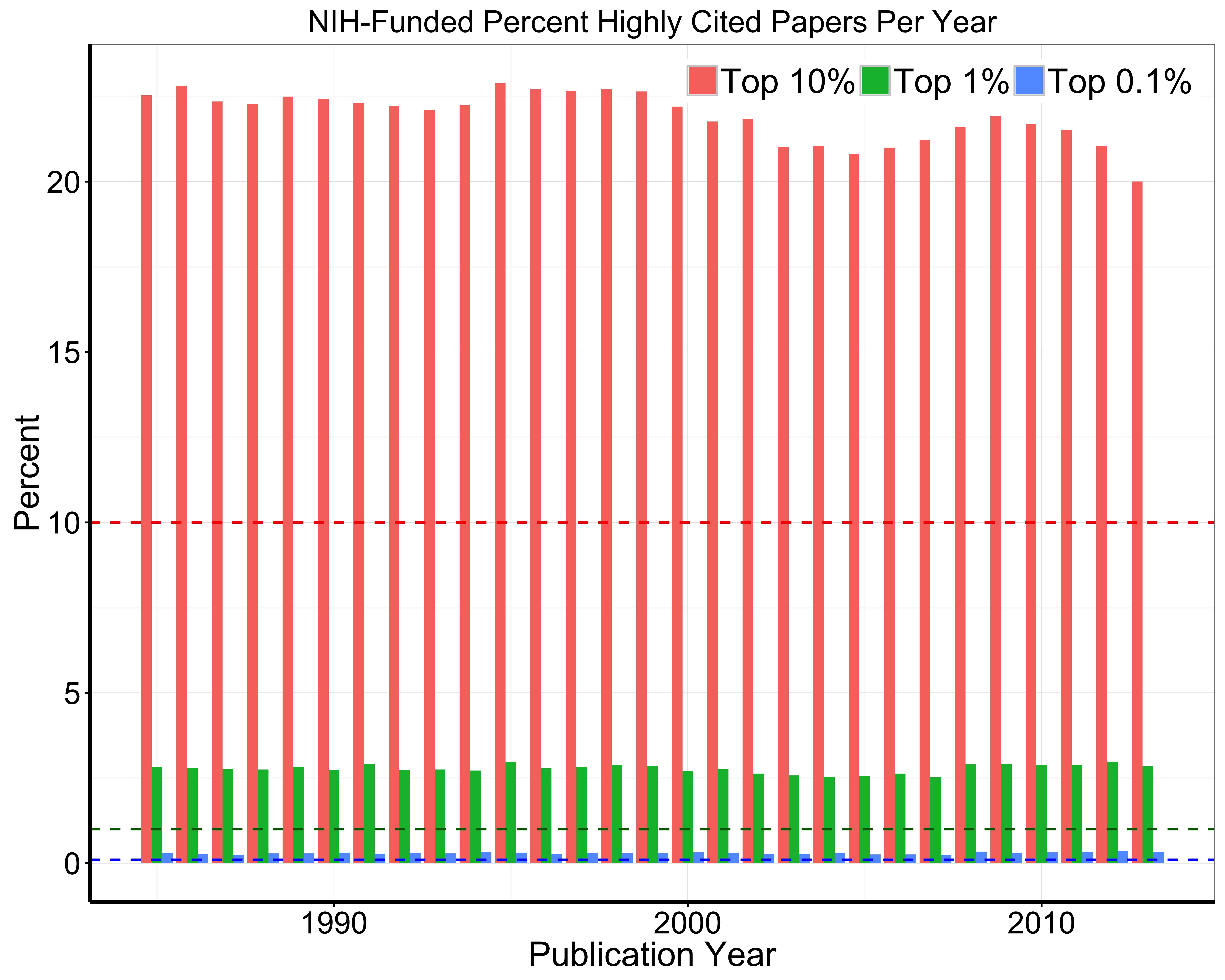
One approach, to go beyond raw citation counts and control for factors such as citation behaviors and time, is to empirically bin papers according to topic, year of publication, and article type (e.g. research article, review article). Within each bin, we can assess the citation ranking of a paper: whether the paper is among the top 10% cited, the top 1% cited, or is among the hottest papers in its bin- the top 0.1% cited. To understand how NIH-supported papers fall into each of these three tiers, we used Thomson Reuters’ Web of Science to describe the citation impact of 1,578,607 papers published since 1985 that identify at least one NIH grant as a source of support. Looking across bins at the “top 10%” tier, NIH-supported papers were represented over twice as much in comparison to all papers (344,072 NIH-supported papers, or 22% of all NIH-supported papers, fell into this “Top 10%”-most-cited tier). Looking across bins at the “Top 1% cited” tier, there were three times as many NIH-supported papers in comparison to all papers in the database (44,404 papers, or 2.8% of all NIH-supported papers, made the “Top 1% cited” tier). And finally, NIH-supported papers were represented nearly three times as much among the “hottest” papers or the top 0.1% tier. (4,822 NIH-supported papers, which is 0.31% of all papers, were represented in the top 0.1% tier).


Table 1 shows the 25 most common journals where the papers appeared. The five most common were Journal of Biological Chemistry, PNAS, Biochemistry, Journal of Immunology, and PLOS ONE. Table 2 shows the 25 most common topics. The topics were defined by Thomson Reuters from among 226 possibilities; many papers could fit into multiple topics, so here we show the topics in which they had the best citation performance. The five most common topics were biochemistry and molecular biology, neurosciences, oncology, pharmacology and pharmacy, and immunology.
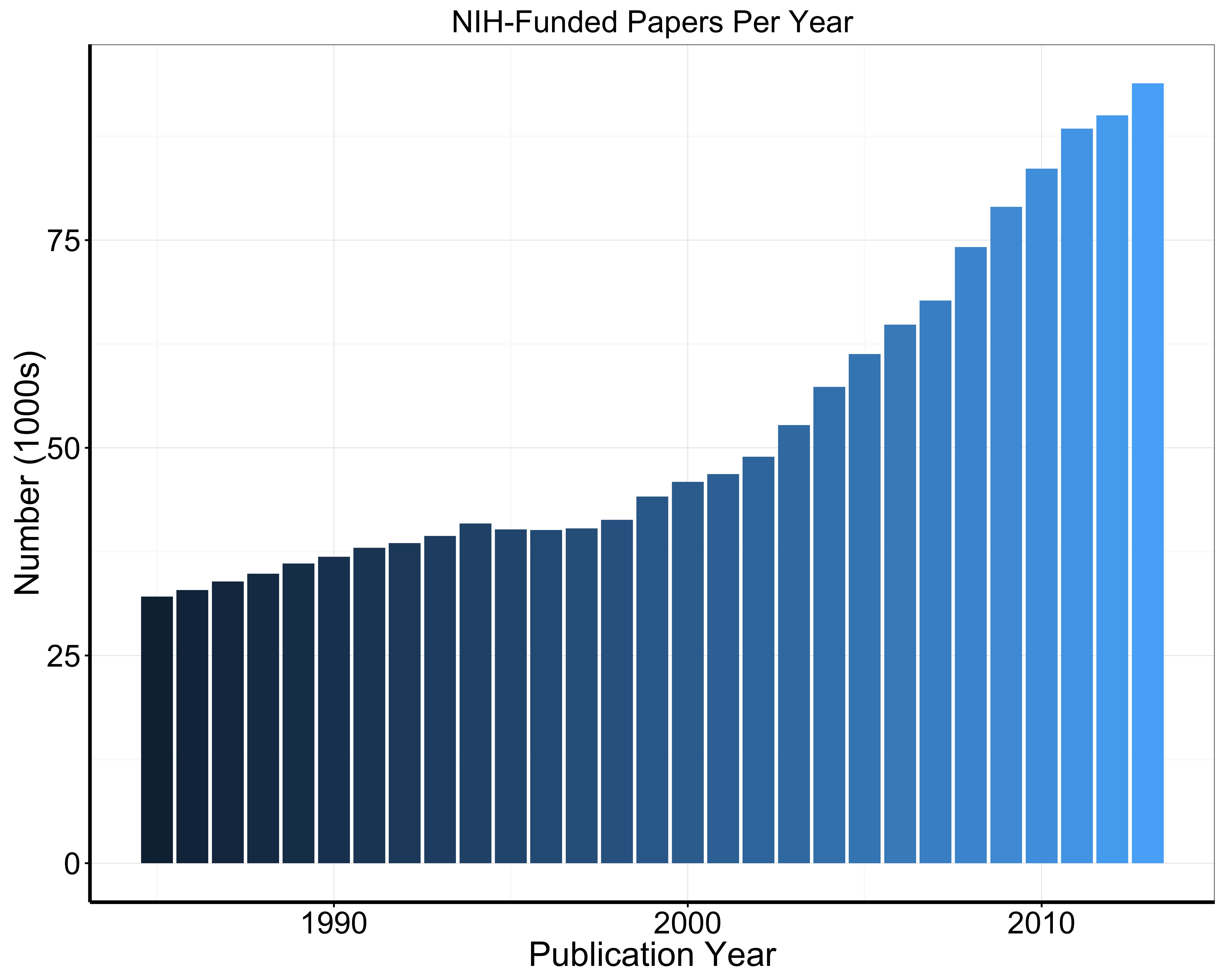
One might wonder about trends over time. In Figure 1, we show the number of published papers per year. There was a marked increase in NIH-supported publications around the year 2000, shortly after the doubling of the NIH budget began in 1999. In Figure 2, we show the proportion of papers that were among the top 10%, top 1%, and top 0.1% most cited. The bars show the actual proportions (in percent) while the dotted lines show the expected values. Though there has been a slight decline in the proportion of NIH-supported papers among the top 10%, NIH-funded papers are highly represented in these top tiers of papers, consistently performing well over time. This indicates NIH-supported research is highly regarded in the scientific community, based on the number of times that community acknowledge the research in their publications.
In future blogs, we will consider an alternate approach to measuring citation impact by field and timing of publication. One exciting method is the “Relative Citation Ratio,” which has recently been released by my colleagues in the NIH Office of Portfolio Analysis.
There are many other questions to consider, some of which we have addressed in prior publications focusing on specific institutes, like the NHLBI and the NIMH. How many highly cited papers are published in proportion to the funds awarded per year? What associations are there, if any, with grant mechanism, type of research, and PI background? Lots to think about!
How represented was NIH funded research in the bottom 10%, 1% and 0.1% of all papers? The NIH is the largest funder of research in the US, so it wouldn’t be a surprise to me if NIH supported papers were highly represented in the bottom dregs of papers published either.
It is mathematically impossible to be over-represented in all percentiles. In other words, if the category of NIH funded papers is over-represented in the top percentiles, that has to be balanced by under-representation in other percentiles. Otherwise this all would sound like the Lake Wobegon joke where “all the children are above average” (assuming local average).
Citations are also frequently not given when they should be. For example, much of the new biology being discovered in vertebrates has already been discovered in model organisms and, very often, the authors fail to cite the published model organism studies. Whether the authors don’t know about the findings (which they probably should or at least they should find out before publishing their new findings) or whether they think citing the previous studies will somehow reduce the impact of their work is not clear.
Seriously? This has to be the most absurd analysis I’ve seen yet. OF COURSE you’re going to find that NIH support led to papers, including some highly-cited ones.
You guys seem to have totally missed the point. Many of us researchers (and definitely the public that pays for it all) want some measure of ‘productivity per dollar’.
Granted, ‘productivity’ is tough to define. But citations is not a bad start. Take your citation counts and calculate some ‘citations per dollar’. Then compare different institutions, labs, and even countries. See who gets the most ‘bang for the buck’, and incentivize those practices.
Is this so hard? Or are you trying to cover for certain places and people that will come out looking bad?
This measure would also tend to favor research areas that are hot, but not less hot areas. And some papers are recognized as being an important insight until years after their publication. So I feel a citation index would not be the best way to measure how important a research project might be.
Publication is controlled and regulated scientific communication. It has become a business thriving on the scientists, since it is a major criterion for academic promotion and funding. Instead, the measure of impact from a scientist or laboratory should be determine based on the value and transparency of all results. Given the advances in technologies and big data, there should be a centralized website similar to Pubmed where all NIH funded investigators are asked to provide all data, positive and negative.
This is a good suggestion to establish a centralized general monitoring site for research quality and productivity.
I think the derivative of citations (and throw in some $$ denominators to mollify the “bang for the buck,’ management-by-metrics crowd if you really must) is a better measure. For example, how much groundwork was done on comparatively “unimportant” subjects to prepare the stage for new, sexy, impactful paper. Someone may publish a hot new fossil finding that happens by a combination of chance and hard work. Without the earlier field work of geologists, evolutionary biologists, and paleontologists in relative obscurity, the “big” paper would be impossible. This analogy applies to medicine, molecular biology, genetics, etc. So papers cited by impactful papers should be just as important as the big ones themselves. We all “stand on the shoulders of giants,” after all.
This whole argument is silly, to me. Citizens don’t want to throw their money away. but at the same time, no one an expert on the future. We already have the imperfect process of peer review as a gatekeeper. Justifying by dollar vs citation count at such a level of managerial detail smacks of intrusion and interference with the peer review process, which I think most of us would argue, is best left to scientists to struggle with. Adding more pressure to “upgrade” papers can only lead to exaggeration and may increase instances of misconduct. It will inevitably serve to further degrade the sense of community among scientists and foster antagonism in an already stressed environment.
The best judge of success is other scientists. That is why peer review is so critical. Is a paper that makes a fundamental discovery, but it takes 15 years for it to find application, less impactful then a paper that makes bold claims but does not hold up, yet received many citations?. The fundamental paper may not have a citation “explosion” until that application starts to occur so it may start building citations slowly and only years later be recognized. Peer reviewers should recognize this when they review renewal requests. This push to provide tools that let non-experts “quantify” quality is part of what is leading to the crisis in reproducibility. “Splash” is rewarded more than solid science. Add to that grant proposals that minimize methodology and we have a system bound to produce the very results that are of concern.
One good measure would be the number of specific aims in the proposal that have been achieved (or to what degree they have been achieved). Proposal reviewers and NIH staff have spent huge amount of time to evaluate the aims and decided that they are important. In most cases, if the aims are achieved or most of them are achieved, the money is surely well spent. I believe that it is not that difficult to determine if an aim is achieved or not, or to what degree it is achieved. For example, in the report, let the PI give a number or percentage and the PO give an approval. Of course, the amount of money for the work will need to be considered as well, and that is not difficult to do as well.
The importance of publications cannot be understated, and the ability to assess the relative impact of a publication through its ensuing citations is a useful metric as well. Yet, the bigger challenge/opportunity for the research community is–as Dr. Lauer observes in the opening paragraph, “the research enterprise should instead focus on its outcomes – its discoveries that advance knowledge and lead to improvements in health.” I’d love to see the publication become the means, rather than the end, as it frequently the case now (publish the paper, hope it gets read by the right person who can effect health/healthcare change, while moving on to the next grant). I hope we can evolve toward an impact factor that looks at how patients, practitioners/MDs, policy-makers, and other stakeholders receive and apply the research in real-world settings. That is true impact.
Wrong. It’s like saying ” Let’s find other planets, so we can sell new land to sell for big $”…
Should we sponsor more salespersons? because those bring the most profits!
Does anyone believe anymore that, nowadays, ONLY ONE scientist comes up by himself /or herself with the scientific breakthrough? — ignoring the evidence that the (so called ‘new’) discovery sits on the shoulders of MANY OTHER (less publicized, less commercialized) discoveries of other scientists (i.e., local and international colleagues)?!?
Research is not about money. It is about scientific discovery. Money shouldn’t be the main driving force.
The number of citations and quality of the journal are a good start, but there is no fair way to judge the results.
How many discoveries have started in peculiar places, by unknown scientists, and turned out later as huge breakthroughs?
Should we invest only in companies like Coca Cola because those are the only companies that can bring the US economy higher? But not the small unknown companies that actually have the biggest potential for growth?…
As Mike Lauer suggests, citation impact factor may be the only good metric available to look at how useful an NIH funded research is, to the broader scientific community, and ultimately to the public. With the proliferation of PubMed cited predatory journals, it is very easy to generate publications for a few hundred dollars (quantity, not quality). As such, impact factors can weed out these for anyone looking at an NIH CV for “productivity”. I just wish NIH would make the requirement that applicants list the Citation Impact factor at top of the publication list in NIH CVs for R01 applications etc. If so, investigators will be forced to produce quality research instead of being involved in a numbers game to pad their CVs with sub-standard publications in any of these predatory journals that are cropping up everywhere. A publication generated using NIH funded dollars that garner zero citations over the years is a waste of federal tax dollars, a waste of effort, a waste of trees. Only benefit is for the investigator – to make the CV impressive and perhaps to help support promotion and tenure – provided the P & T Committee at the investigator’s institution looks at quantity, and not quality. Sadly, that is becoming the norm.
As scientists, we are all aware of the potential for unrecognized artifacts in any single experiment. We should take the same view of the metrics we use to evaluate productivity. The public, who contribute the $$ that fund science, want to see “impact” for $$ spent. The perception of that impact shifts with time (consider the Apollo program). Scientists perceptions also shift with time.
I think a citation metric is one useful, but imperfect factor. There are both the “h” factor and the “g” factor, as well as others less familiar to me. NIH should request multiple metrics to account for potential artifacts. But scientists need to start reaching out to lay people to help re-ignite some excitement about science in all its forms. Funding will always be lower in a bad economy, but it will be the lowest when tax-payers see no value in basic research.
… and the NIH/NHLBI fiddles as the scientific community burns… trying to find a scoring system that will justify the current sorry state… yet the medical treatment of cardiovascular disease with few exceptions has changed little in the past 30 years, with b-blockers, ACEI and statins the mainstay of therapy… SO what is the true impact, and impact on human health, of these supposed high impact (but largely/often irreproducible) papers claiming to have discovered new treatments for heart and vascular diseases.
Papers that are false are highly cited and rarely are papers published that address a published lack of reproducibility. A Nobel prize winner told me that he could never publish papers that contained mutations that had no effect, and yet the lack of effect points to regions of a molecule that is not involved, but no one can read that.
We all know the wave effect that some key figure writes a paper that goes viral and everyone starts doing it. Does that mean it will be significant in 25 years? No one knows how to predict the future.
Let me suggest that the NIH limit the number of publications/year/grant to 2. That will make the published papers more thoughtful and provide more trustworthy data. We are swamped with weak papers. Numbers don’t matter, only scientific quality and that often cant be measure for a decade or two.
As long as we are at it, NIH should limit the cost of a publication, say to $1500. People with big grants will pay $5000 to Nature Comments and get cited, but people with low funding have to go to less cited journals and that has nothing to do with the quality of the research.
Citation derived measures are not a helpful! To see this, consider the number of high-impact (Nature, Science, PNAS) publications that are not reproducible!! The citation counts for the original publication, and all citations using the results as a basis for the subsequent study, and the citations to those, and so on creates a highly biased measure …. In fact, there should be a way to give negative scores!
Normalized citations of fully reproducible research per dollar spent is the measure to go after. For this to be meaningful, NIH needs to deal with the many hundreds of irreproducible research papers.
I have seen some verbal acknowledgement about reproducibility coming from NIH, but this effort by the NIH is considered to be more of a “dressing” by the community that really understands reproducibility – of course, no one likes to be too critical.
If you want impactful research, address the reproducibility problem.
When one considers the impact factor, it should NOT be for the journal, but for the publication. Yes, PNAS, Science, and Nature have some of the highest JOURNAL impact factors, but they also have some of the highest retraction rates thanks to much higher scrutiny of papers published in them. The journal should not matter [as long are these are not non-peer reviewed (or fake peer reviewed) online journals listed on PubMed]; if original ground breaking results that move the cancer field forward gets published even in a lesser ranked journal including open-access ones, it will soon be followed-up, cited and built-upon by others.
As for non-reproducibility, that has become the greatest danger to the biomedical research enterprise. It all depends on the honesty and integrity of the researchers and the PIs. Sadly, these qualities appear to be in increasingly short supply, as evidenced by reports in research watchdog websites such as PubPeer and Retraction Watch.
Publication Counts Versus Citation Counts
Publication counts provide a primary metric for scientific productivity and are used by NIH officials to measure thinks like return on taxpayers’ investments and to optimize funding allocations (e.g., JM Berg, 2012; JR Lorsch, 2015). This is a robust and useful metric, provided that it is normalized to total funding (all sources, direct and indirect costs). However, the metric provides no insight into the “impact” of the publications.
Mike Lauer suggests that citation-based metrics provide a useful tool to gauge the impact of NIH-sponsored research. However, I contend that such metrics lack the precision and accuracy required to make any meaningful policy decisions. Here is why:
First, as pointed out by Debbie Andrew, authors themselves can have a positive impact on citations of their own work by failing to cite seminal work (and in some cases essentially identical findings) published by others. Whether by intent, ignorance or journal limits on the number of references, this practice reduces the citation impact of both ground laying and seminal work.
Second, as pointed out by Lee Ann, citation-based metrics tend to favor research areas that are perceived to be hot. Similarly, the fact that a paper is published in a “hot” journal increases the likelihood that it will be cited, even if the study itself is not so hot. And the identical paper published in a journal with a lower impact factor would likely garner fewer citations.
Third, there are strong biases in grant application success rates between institutions and even between whole states. Such institutional and geographical biases likely also affect journals’ decisions on which papers to publish and authors’ decisions on what papers to cite, each of which affects citation-based metrics.
Fourth, normalizing citation data by field (or topic) imparts more imprecision. Most research is highly focused and citations of such work are, necessarily, normalized to broader, arbitrary topics. For example, citations of a meiotic cohesin paper might be normalized to biochemistry or to genetics, each of which would give a different normalized impact—and neither of which is appropriate for the actual, narrow field. (Relative Citation Ratio, which attempts to address this issue, has its own limitations.)
Fifth, the citation data cannot distinguish between scientifically robust citations (authors read the paper they cited) and less compelling citations (authors cited secondarily from someone else’s reference list or an abstract). In the old days, references were not corrected electronically and it was easy to find unique, newly arising citation errors (e.g., wrong page numbers)—and to trace all of the lazy authors who subsequently copied the reference list citation (with error) into their own reference lists. This practice of citing without reading is common and its effect on citation rates can compound over time, like jackpot mutations in a Luria–Delbrück fluctuation test.
For such reasons, I contend that citation-based metrics cannot provide an accurate measure of the value of scientific work sponsored by the NIH. Unless and until the bibliometrics wonks can account quantitatively for multiple sources of bias and imprecision (examples above), inferences about “quality”, “outcome” or “impact” made using citation-based metrics should be interpreted with caution.
All that was great about publication counts for research productivity prior to the genesis of predatory journals. Nowadays, quite a few of these get listed in PubMed. If one needs to just pad-up the publication count, all you need to do is submit half-baked manuscripts/LPUs (least publishable units), along with the usual few hundred dollar fee/bribe for publication costs to the online journal, and voila….! you get a PubMed citation sometimes in just 24 hours, at most in two weeks. If the NIH reviewers are still counting publications when evaluating an applicant’s productivity, I would be sorely disappointed with them.