
16 Comments
In order to develop and implement data-driven policy, we need to carefully analyze our data to understand the “stories behind our metrics.” Without analyzing our data to know what’s going on, we’re essentially flying blind! A group of authors from the NIH Office of Extramural Research sought to investigate the stories behind peer review scoring and why some grant applications are more likely to be funded than others. They extended analyses previously reported by NIH’s Office of Extramural Research and National Institute of General Medical Studies. Last month, they published their analysis of over 123,000 competing R01 applications and described the correlations of individual component peer review scores – significance, investigator(s), innovation, approach, and environment – with subsequent overall impact score, and funding outcome.
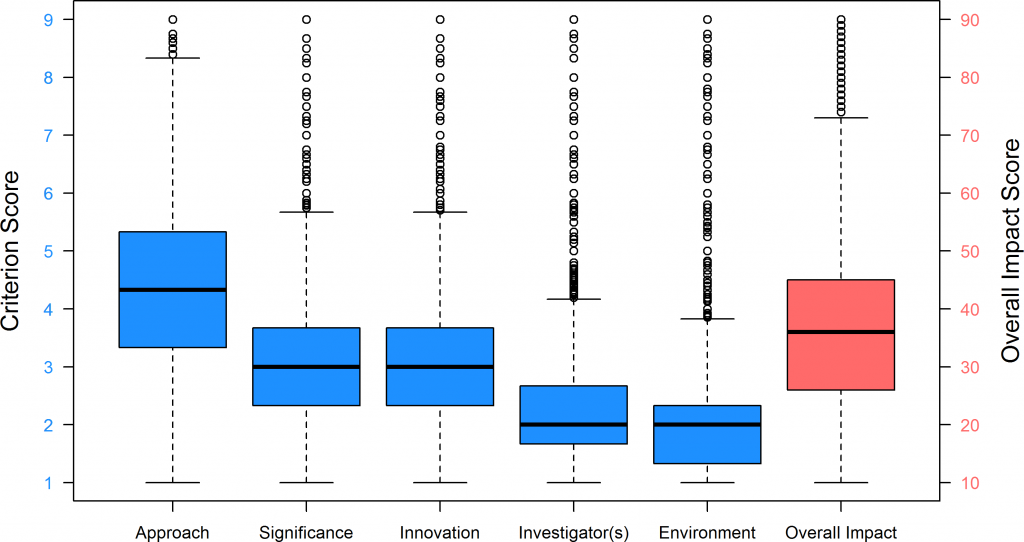
NIH’s use of these criterion scores began in 2009, as a part of the Enhancing Peer Review initiative. The authors analyzed data regarding R01 applications submitted in fiscal years 2010-2013, and constructed multivariable regression models to account for variations in application and applicant characteristics. They found that by far an application’s approach score, and to a lesser extent, the significance score, were the most important predictors of overall impact score and of whether any given application is funded.
What does this mean for you as applicants? We think it’s helpful for R01 applicants to know that the description of the experimental approach is the most important predictor of funding, followed by the significance of the study. As an applicant, familiarizing yourself with the peer reviewer guidance and questions they are asked about approach and significance may be helpful as you put together your application.
The authors leveraged their data to examine a number of other potential correlates of funding. For example, they find that the New Investigator status of the R01 application is positively associated with funding outcomes. This lends even more support to our recommendation that early-career applicants and investigators should familiarize themselves with new and early investigator policies when considering submission of multiple-PI applications, and applying to NIH.
The authors also report some interesting data consistent with previously reported data on funding outcomes by race and gender: women were slightly less likely to be funded than men (rate ratio 0.9, P<0.001), while black applicants were substantially less likely to be funded than white applicants (rate ratio 0.7, P<0.001). However, when the criterion score were factored into the regression models, the demographic differences disappeared (for women adjusted rate ratio 1.0, P=0.22; for blacks adjusted rate ratio 1.0, P=0.73). In an upcoming Open Mike blog post we’ll discuss additional data related to this topic and steps NIH is taking to address these issues.
I’d like to thank the authors of this manuscript for this analysis and congratulate them on their publication.
If gender and race differences ‘disappeared’ when matched to criterion scores, this does not mean that bias disappeared– it’s just hiding in the Approach section.
I’m still waiting for NIH to address the outrageously gender-biased outcome of the ‘4D Nucleome’ Common Fund project– 51 of 53 funded PIs were men, and 30% were ‘insiders’ with other recent Common Fund grants. Do you have any information?
I fully agree with Dr. Wilson. If women and URMs are getting lower criterion scores, this needs to be taken seriously by NIH. Also, it is long past time for NIH to examine the extreme gender skew in the 4D Nucleome outcomes.
This is interesting but begs the question of whether the association between the approach and overall impact is descriptive or normative. Just because reviewers think this way does not mean that it is the most desirable way to weight scores across the different dimensions. Personally, I think the significance and innovation should drive the overall impact and that too much emphasis is placed on approach. I don’t mean to say that the approach is unimportant, just that it is the easiest place to find even a few minor weaknesses that drive the score up. And since scientists are trained in research methods, most of us are hard pressed to give an overall score of 1 or 2 when the approach is scored at a 3 or 4, even if the proposal is otherwise promising. All of this presumes that the weighting of domain scores is assessed logically and systematically, when it is likely that many reviewers actually work backwards from an overall impact score to the individual domain scores at least some of the time. In this way, the domain scores are entered post hoc to justify an overall impact score that is based on an overall subjective judgment that is either favorable or unfavorable. This is not necessarily a bad thing, but it is probably not how the system was designed to be used.
My understanding is criterion scores were instigated so that reviewers would look beyond the Approach section. If so, it didn’t work.
Asking whether race and gender affected funding seems to be the wrong question. Do women and racial minorities get lower scores? Sounds like they do. Given previous research on the effects of applicant gender on subjective scoring, this might be worth looking into.
It’s pretty disappointing that reviewers consider methods over twice as important as significance and over 5 times more important than innovation.
A recipe for stodgy science.
I think the Environment section is ridiculous in this day and age – I have always felt like it is only possible to score a 1 if one works at Harvard or similar institutions. IMO this should really be a yes/no question – why does it matter where I am located? So long as I have the equipment and/or collaborators that I need to get the work done, this should just be a YES. Likewise, if I am proposing to do something that I simply cannot (e.g., PET when the nearest isotope production facility is 800 miles away) then this is a NO. “Grading” where I work is just ludicrous.
So how is an application going to receive a fair and unbiased review if study section members lack the expertise to evaluate the approach that is being proposed in the grant application? It’s obvious that discovery technologies get unfairly criticized because most study section members lack the expertise to evaluate the strengths and weaknesses of these experimental approaches. This is why only generic and mundane experimental approaches are well received at NIH study sections. The applicantion cannot propose an experimental approach that is smarter than the study section members evaluating it because the reviewers would have to come out of their experimental bubble and stick their neck out to defend something they lack the expertise to judge. So the easiest remedy is to say it’s “too risky” or its a “fishing expedition” to disqualify an honest and fair evaluation of the experimental approach. Biomedical discoveries require experimental risks and the current NIH culture at study sections does not allow for a fair and unbiased review of discovery approaches grounded in experimental biology. Please wake up NIH and be proactive in the support of basic science through the support and funding of high-dimension discovery research approaches.
This just shows that reviewers correlate the quality of science in the grant with the approach section. Many of the rest of the criterion scores are frankly window dressing. “Innovation” is most often read as “new/cutting edge techniques” and not as “new fundamental insights into a disease.” In my mind, the latter is true innovation, the former may be but often is merely inserting enough new techniques to camouflage the same old fail approaches. “Environment” is pretty much useless since so few ever seem to get a low score. “Investigator” is the usual volumetric measure of scientific output and not a measure of productivity relative to dollars awarded, which would be more enlightening in many cases.
I’m not convinced, as many correspondents are, that weighting the Approach section heavily is a problem. Evaluating the Significance of a proposal is quite subjective, but I think most of us who review can tell a flawed experimental design, or an experiment that doesn’t really answer the question. And in my experience, Study Sections can evaluate when high-dimensional analyses are purposeful, and when they are merely fishing. Innovation is important, except when it isn’t; for example if it is trumped (excuse me!) by Significance. And I agree with previous comments that the Investigator and Environment scores are mere fluff, and we rightly ignore them most of the time. So it seems to me the Approach section is most heavily weighted in part because it is the closest to an objective evaluation.
Methods are important if they are fatally flawed or will lead to misleading results. My experience both as an applicant and study section member is that many reviewers tend to nit pick methods because that is easy.
This is a particular problem in light of the page limits, which do not allow enough space to discuss every possible nuance in the methods.
I find the comment more interesting than the article!
Institution More Important Than Race
Mike Lauer points out, citing data from Table 4 of the paper, that there are differences in the likelihood of funding associated with race and gender of the applicant. Neither Lauer nor the authors address a more interesting aspect of data in that table. The investigator’s institution has a greater impact on funding than race or gender.
The magnitude of this impact can be seen in Table 1. Grant applications from the 30 top-funded institutions were 19% to 66% more likely to be funded than those from institutions in the next three bins; even though there were no significant differences between the average impact scores from scientific merit review (mean impact score range of 35-38). The disconnect between impact scores and success rates raises the intriguing possibility that administrative review contributes more to institutional funding disparities than does scientific merit review.
The data on the disproportionate allocation of NIH R01 grants to a subset of “preferred” institutions recapitulate findings on the distribution of discovery grants by the Natural Sciences and Engineering Council of Canada:
The broader issue, illustrated nicely by data in both papers (and others), is that different groups of scientists do not have equal access to federal funding for research. To promote a more diverse and productive research enterprise, the NIH needs to address the strong disparities (biases) in funding between investigators, institutions and states.
The curator stripped out my hyperlink to the Canadian study. Here is the “link-free” citation information: Murray DL, Morris D, Lavoie C, Leavitt PR, MacIsaac H, Masson MEJ, et al. (2016) Bias in Research Grant Evaluation Has Dire Consequences for Small Universities. PLoS ONE 11(6): e0155876.
The study has a major flaw (well, two, actually). The second flaw is the inability to correlate scores with underlying “reasons”. For example, looking at sex disparities in funding, I almost always know if the PI is male or female by the name and sometimes the letters of support. So if I carry a hidden bias (I hope not) it will very frequently appear, and no amount of “normalization” will lessen its impact. Race, however, is frequently not easily detected. If I am racially biased (again a disturbing prospect) it will be more difficult to demonstrate based on scores alone, and more knowledge of the fundamental reasons why scientifically equivalent proposals are scored differently by me according to race. That can only be determined through a carefully designed interview or questionnaire for each individual score. That is just not possible. The first flaw I referred to is that the analysis essentially treats the categories as independent. They are not. The Significance score of my own submissions clearly influence the Approach score. If I haven’t convinced a reviewer that my proposal is highly significant and amazingly innovative, reviewers also work harder to find Approach flaws. I have often found that I can have the strongest impact on my resubmission when I strengthen the perceived Significance. After all, who wants to get caught telling the applicant he has an outstanding design for a non-important question? A valid analysis of how scores are weighted across the categories to derive the final score must be able to model the complex interactive relationships among the categories
The above discussion mostly focuses on the unique relationships between individual criterion scores and overall impact / funding. I was pleased to see that the actual paper presented the correlations among criterion scores. The scores are all moderately to highly correlated — indeed approach and significance are correlated .72 (which has to be pretty close to the boundary set by reliability). Although I share the sense that too much emphasis on approach can take us in a bad direction, I also believe approach is quite important. The intercorrelations give me hope that it is the shared variance among the criterion variables that contributes a lot of variance (though I still marvel at the attention [we] reviewers pay to approach on R21 applications).
I also wondered about interactions between criterion scores, such as sig x approach or innovation x approach. One might hope that a proposal weak on sig / innovation would not get funded regardless of how beautiful the approach (though the high positive correlations suggest reviewers rarely see applications that way). The paper does discuss one such interaction — sig x approach. I wish that there had been a graph and/or better description of that interaction in the paper. Maybe it was there and I missed it…?
Overall, I really appreciate the paper. It allows us to debate with data, rather than waving our arms at a ‘black box’. Along those lines, it will be cool if the data are available (they may well be) so that one could examine other / more specific questions, such as the degree to which the relationship between criterion scores and funding is stronger for some institutes compared to others.
Mike: Interesting. But as a step to “implement data-driven policy”, this study seems to miss the point of reviewing: to answer the question, *Is NIH funding the RIGHT projects?* That is, ones that demonstrably improve the health of the American public, or similar focus on NIH’s mission.
Yes, that’s hard, and it generally takes a long time to get definitive outcome data (though not necessarily to get *useful* outcome data). Also, you may need to look at many projects that NIH reviewed but DIDN’T fund, but that some private organization later did, to see if NIH is just taking its eye off the ball, whether through reviewer failures, a misconceived scoring system, or even misguided priorities.
Yes, hard. But surely you can get valuable — and validated! — insights from studies far smaller than 123,000 competing R01 applications.