
18 Comments
A critical component in assuring the efficacy of NIH’s peer review system is the continuous assessment of peer review activities, to be sure that the practices and policies uphold the core values of peer review. In fact, this continual assessment was a key component of the 2008 NIH Enhancing Peer Review Initiative.
These continuous assessment activities include ongoing analysis and monitoring of peer review outcomes as well as online surveys to give applicants, peer reviewers, and NIH staff the opportunity to weigh in on our peer review process.
We’ve posted a report of the most recent (Spring 2012 Phase II) surveys on our peer review web pages. (As described in the report, Phase I surveys took place in Spring 2010 shortly after peer review changes were made.) Overall, applicants and reviewers are more satisfied with the new peer review system than the system in place before the Enhancing Peer Review initiative. Most respondents rated the peer review system as fair and consider themselves satisfied with the peer review process.
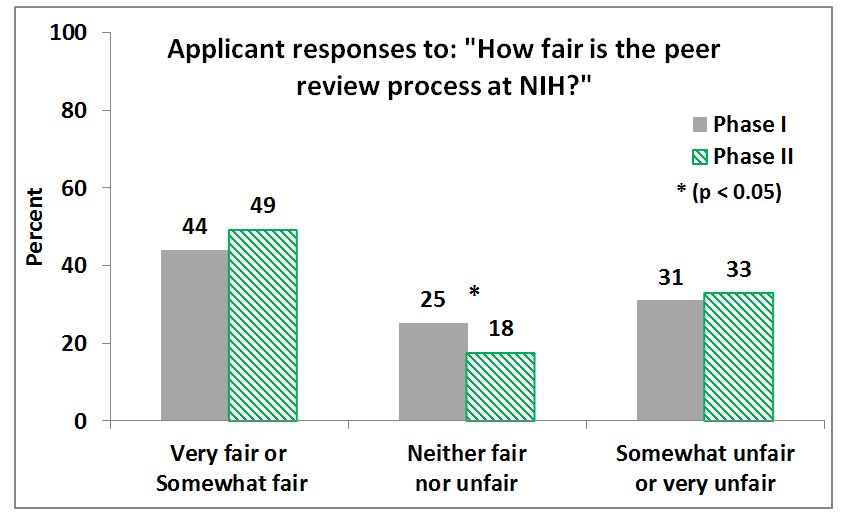
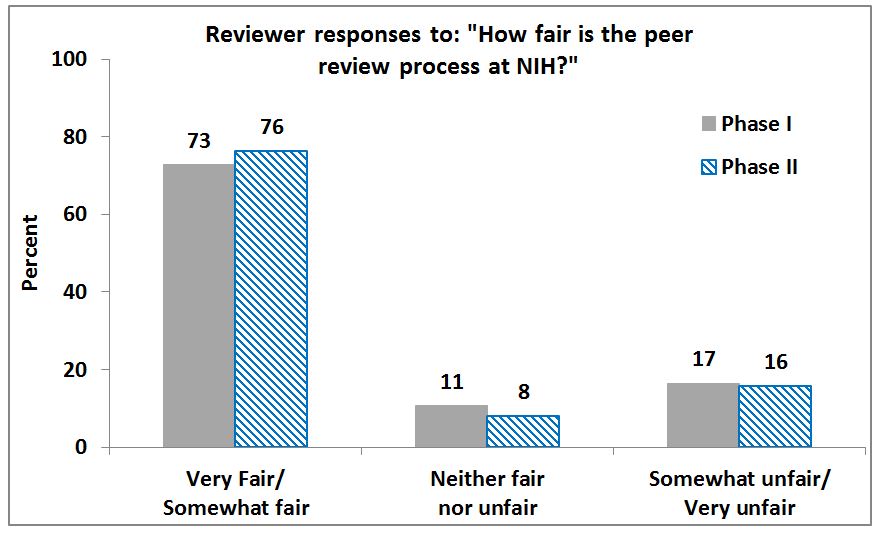
The report asked program officers, scientific review officers, applicants and peer reviewers about specific aspects of the Enhancing Peer Review changes (such as single resubmission and nine-point scoring), and we are continuing to examine the impact of these policies, and provide guidance in response to these concerns. For instance, in open-ended comments, reviewers responding to this survey expressed their concern for uneven use of scores across the 9 point range, and a need for more scoring guidance. NIH recently issued revised scoring guidance to encourage use of the entire scoring range.
As I’ve said before on my blog, we are committed to continuous review of our peer review system because we know as science evolves, so should our peer review processes. Thanks for participating in these surveys.
The problem with the scoring system is that there are two goals that scores provide: first, they need to provide a ranking so that NIH can do its best to fund the best and most important science, second, they provide a signal to applicants of how good their grant was. This second component is absolutely critical to new applicants learning the grant-writing ropes.
As reviewers, we are getting conflicting statements from NIH. On the one hand, we get statements about what a score of “2” means. On the other hand, we get demands to “spread out the scores”. The problem is that if a “2” actually has meaning, then it is very possible that all of the grants we get will deserve a “2”. In other words, the ranking and signalling goals are in conflict. Much of the unhappiness with the scoring system comes from the conflict between these two goals.
Any scoring system needs to provide both RESOLUTION and RANGE. There must be enough resolution to differentiate applicants and enough range to capture the full set of applications. As with any high-end competition, there is a strong self-selection process in NIH grant applications and most of the applications are excellent, but a few are terrible.
The 1-9 integer scoring system attempts to provide both resolution and range by abandoning linearity. A score of 3 is much closer in quality to a score of 2 than a score of 9 is to a score of 8. This has the major disadvantage that it is very hard for reviewers to work with non-linearity.
In the old 1.0-5.0 system, resolution was accomplished by having decimal numbers and range by allowing the full scale. In the study sections I saw under the old system, grants clustered between 1.5 and 3.0, with small tails above 1.5 and below 3.0. This meant that a truly terrible application could be assigned a 4.5, saying “this isn’t even close. try harder next time.” But there was still resolution to differentiate the good applications (15 rankings, which is larger than the 9 we have now).
The problem is that there was very little difference between a 2.1 and a 2.2. Did we really have the ability to distinguish between these? However, grant applicants needed to recognize that this is a statistical problem – there is a real score plus noise. So a 2.1 was marginally likely to be better than a 2.2, but a 2.0 was almost certainly better than a 3.0.
When the 1-9 system was introduced, the original stated goal was that we couldn’t tell the difference between a 2.1 and a 2.2, so we should just call them both 2. But then we had strong clustering in the 2s and 3s. (This should have been expected.) However, the message we are getting now is that if all the grants are 2s, then there will be too many grants in the 2 category, and study section has no real purpose because program has to make decisions between funding grants with identical scores. Therefore, reviewers are now being asked to “spread our scores”, which abandons the signalling aspect. One potential solution is to actually rank the grants, which is the ultimate abandonment of the signalling aspect. (Important note to CSR – if we are simply ranking grants [which is what “spreading scores” means], then you cannot say “a score of 2 means a high impact grant with few or no weaknesses” because lots of grants fit that description.) Ranking grants becomes a problem in SEPs and study sections that see only a very few applications.
I first started doing reviews at the tail end of the old 1.0-5.0 system. I was very skeptical of it at first, but the more I worked with it, the more I appreciated that a 2.2 really was marginally better than a 2.3, and the more the system made sense to me. As a new reviewer, I realized that study section was doing its best to differentiate grants that really were both excellent. As a junior faculty, I was able to recognize how my grants were doing from the scores I got. We have now had a number of years with the new 1-9 system. The more experience I have with it, the less I like it and the less it makes sense to me.
NIH needs to return to a decimal system, providing linear range and extra resolution. This could easily be accomplished by providing decimals to the 1-9 integer system.
It has been suggested that the written reviews can provide signalling, but the written reviews are very hard to interpret because they are statements written by individuals and open to interpretation. Having a set scoring system that can provide signalling would provide a better way of communicating to applicants.
This is an excellent assessment, going from a system with an effective range of 40 points (1.0 to 5.0 by tenths) to a 9 point system clearly results in difficulty discriminating.
I agree as well with these cogent points. Adding back decimal points to the scoring system is needed, or else the scores will inevitably be bunched and increasingly meaningless.
I completely agree with this assessment. The NIH created the problem of score compression by reducing the number of possible scores. Being forced to spreading scores within a package of 9-10 grants is less fair than applying decimals. But there will be no changes, based on how happy Dr. Rockey seems again with the way the system works. The last time that there was an uproar (about restoring the A2), she was very quick to point how great these changes were and how well everything works. They live in a different reality.
I have to disagree with “….Most respondents rated the peer review system as fair and consider themselves satisfied with the peer review process…” More than 50% of applicants thought that the system is “neither far, neither unfair” or “somewhat unfair, somewhat fair.”
Thank you for sharing this update on the enhance/improve the NIH peer review process. I wonder if, in light of the findings of Ginther et al (Science 19 August 2011: 1015-1019), might we see a disaggregation of the data tables to show if race/ethnity and gender differences exist?
Thank you.
Ric
NIH did examine for race, ethnicity, and gender effects, but found no significant differences that affected interpretation of the survey results.
Thank you.
Fair is an acceptable way to classify the peer review system. At times, it is know to be a process with homogeneous criteria, however this is okay at times provided review remains objective and critial thinking is maintained. It is common understanding that it is possible to give preferrential treatment, That mentioned, I believe the reviewers choosen can continue to be above board and deliberate with impartial judgement most often. Ethnically, ethically or resource restricted laboratories need to be given a contectual judging eye. Some research uses less than good, normalized or even real (good) data sources, but sometimes researchers have to work within their resources.
It would be very helpful that if all the stakeholders in the scientific peer review process for example, new- early stage- and established investigator come togehter in a forum that would be moderated by both program directors and scientififc review officers to formulate a system that yields a wide spectrum of scores and enough valuable scientific feedback for applicants. Based on the scoring system developed so far, we still have to resolve the narrow band clustering of all applications into discrete sub-stratification reviewed applications that provides actual solutions to the problems associated with poor grantsmanship, design of the study, scientific approach and methodology, disjointed specific aims that do not address the central hypothesis of the proposal besides usual criteria about significance, innovation, environment and applicant’s experience and training.
It would be prudent to organize a workshop or think tank with all the stakeholders and come up with a refined sytem that is conducive, inclusive and coherent of everyone’s input, suggestions, and feedback. We all have to come together and resolve these flaws in a very respectful and collegial atmosphere where everyone’s voice and ideas will be heard and discused in an academic environment to create policy and decision making recommendations for the entire scientific community.
Is there an email address for feedback about the scientific review system? I searched for one, but was unable to find one, which makes me suspect that they are not that interested in suggestions about how to improve peer review. I have some suggestions:
1. Allow applicants to see the unedited reviews before the study section meets, and have 24 hours to provide a 200 word response. I have received on more than one occasion a review that contains a complete misunderstanding of something fundamental in the proposal (sometimes my fault for a poor explanation, sometimes their fault for not reading it properly). A 200 word response to the unedited reviews before study section meets would allow this to be largely avoided.
2. I still don’t know why A2’s were eliminated – I think a scientist’s time is better spent refining a good idea (i.e. that score reasonably well) than trying to come up with an entirely different one. Many of the A1s that aren’t funded would have been funded a decade ago, but are now dead in the water.
3. Allow one 1 new application per year per investigator (but unlimited renewals of course). One of the reason the percentiles are so low is because so many people are submitting many applications (in desperation of getting something funded) – this just drives the percentiles lower, and no-one is prepared to unilaterally disarm. Thus, there is simply a lot of time wasted writing and reviewing grants that will never be funded. Only allow a maximum of 1 new submission per year and this will address the problem to some extent, and people will probably put in better proposals to boot.
4. Sequentially reduce the amount of support that investigators can get for their own salary – research institutions hired faculty like crazy when the NIH budget doubled, but largely on soft money – this is part of the reason that funds are so short. Let’s face it, PIs don’t really do the research itself, yet often need to fund as much as 100% of their salary through grant support. This (over time) should be pushed back on the institutions, who shouldn’t be hiring faculty they can’t afford to support.
5. Try as hard as is feasible to get the same reviewers for A1 submissions as for the original submission – maybe this is already done, but it’s extraordinarily frustrating to respond to a set of reviews only to get 3 new sets of opinions (often in exact conflict with the previous ones!) that torpedo the only resubmission chance you have.
I truly agree that we need A2s to come back – as noted, it is definitely better to refine a good proposal than have to turn it into something else. Moreover, this is tough to do when one is a junior researcher with limited resources – in this case one almost has to put all one’s eggs in one basket, and it is tough to generate preliminary data for a second project if not funded.
I wonder how study section members’ grants fare compared with all submitted grants ? It is assumed that people serving have grants but after one or two cycles on the study section do they fare better than peers who do not serve? I would also separate permanent members from ad hoc in this type of analysis. Also would like to see analysis of final score compared with significance score of approach score. Approach score still ranks as the driver of the score and this may/may not be appropriate for some grants. A grant review board I once served on asked the members to generate a list of worthy grants from the entire pile based on scores and them draw a cut-off line below which they felt that grants submitted in that form should not be cosidered. The five categories currently used by NIH were used in that same system 30 years ago with reasons or outcomes.
In the old scoring system, the Study Section members acted as a group – we could discuss among ourselves whether a grant fit a 1.7 vs 1.9 because we were working off a common set of “rules”. In the current system, the final score depends on how many members independently arrive at either a 2 or a 3. This assumes there is some divergence in reviewer scores after discussion, which is almost inevitable in that “real” scores often lie between 2 and 3 – a range that after all is the only one relevant in resolving among the majority of grants that are worthy of funding. The group does not know the outcome and therefore cannot provide meaningful input or consensus in making the critical distinctions needed, especially in these times when a large fraction of meritorious grants fall within the gray zone.
I really support Dr. Redish’s comments. from the limited NIH peer reviewing that I have done, I recognize that this is a very onerous process for the reviewers. But some of these numbers seem a bit meaningless and don’t always match comments. If I get a score of 2 for the Environment, what does that mean? Just that I am not at Harvard? Investigative teams should be scored separately and thus should not influence this score (although I suspect that they do). So if I have access to all the necessary equipment and resources, how do I not get a score of 1?
Two simple questions:
1. Why NOT just allow reviewers to use decimals on the new system?
2. Why does NIH NOT perform the cross-validation that we reviewers demand of any application, i.e., show (on a sample basis, perhaps 5% of applications) that the IRG judgments going into one application’s review would be nearly same when a different but still appropriate IRG (different readers, different IRG members, different SRA) assessed the same application?
Increasingly, it seems to me that these surveys of peer review miss an important and uncomfortable point. The knowledge and expertise of the SRO of a given study section is one of the most important variables in determining the success of a grant application. This is because matching the expertise of the primary and secondary reviewers with the content of the grant being reviewed is critical to the outcome of the review. Through 30 years of reviewing, I have seen a large increase in what I consider to be inappropriate reviewer assignments. I often have to wince at the ill-informed remarks made by primary reviewers who were inappropriately assigned and don’t seem to realize it. Arguing with them usually doesn’t work and degrades the tone of the study section. My research area has grown and changed dramatically over the past 20 years and yet the chief of the review group is still the same person that was doing this job 20 years ago. In my opinion, the consequences of this fact have been disastrous. The old divisions of the discipline that were in place 30 years ago (e.g. “pharmacology”, “electrophysiology”) are increasingly irrelevant because interdisciplinary departments have become commonplace and the techniques of molecular biology, biochemistry, and cell biology are applied to problems in varying combinations. This seems to foster the false believe that a person primarily trained in, say, electrophysiology or biophysics, can cogently review an application that employs primarily the techniques of, say, cell biology and biochemistry, with just a few electrophysiological techniques employed as assays. Quite a bit of sophistication about the science in the field is required to understand who is an appropriate reviewer, and how a particular reviewer should be assigned. That sophistication is now lacking. My colleagues and I frequently say that submitting a grant to NIH is now just a crap-shoot. The randomness of the review process stems from the low probability that an appropriate reviewer will be assigned to a given grant. Sometimes the reviewer is appropriate and the grant does well. More often the reviewer is effectively clueless and the grant is triaged. The same grant submitted to one study section does very well, but if moved to a different study section it is not discussed. In the present climate in which “pay lines” hover around 10-12%, getting a grant funded becomes a random process. There is no way to alter review criteria or scoring methods to fix this fundamental problem. I believe that the reviewer assignment process needs MUCH more monitoring. I don’t know whether updating of review group administrators, hiring of more sophisticated SROs, or a more closely monitored process (say discussion of ALL assignments among several SROs) is financially possible. Unfortunately, the broken review process at NIH won’t be fixed without it.
SRO needs overseeing,
start with the individual who wrote the draft.